Vgg とは
親知らず 顔 の 歪みVGGネットワーク(VGGNet)とは?要点を爆速rikai入門 . VGGとは2014年に提案されたCNNのモデルのひとつで、Oxford大学の研究グループによって発表されました。 以下のリンクがVGGが提案された論文です。 VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION. この …. 【シンプルに理解】画像認識CNNのVGGを分かりや …. VGGはオックスフォード大学のVisual Geometry Groupによって開発されたモデルです。. お察しの通り、ネーミングはグループ名の頭文字に由来します。. VGGもAlexNetと同様に畳み込み層、プーリング層、全結合層を持っています。. まずは、これらの層がど …. VGGとは?画像認識における人気モデルの解説 | AIト …. VGGは、深層学習モデルの1つで、畳み込みニューラルネットワークの一種であり、画像認識の分野で高い精度を誇ります。本記事では、VGGの特徴や層の深さについて解説し、層の深さがもたらす利点を紹介します。VGGの層の深さが. 畳み込みニューラルネットワークでやっていることの理解(VGG . VGGNetの技術についてアイディアレベルで解説 【Deep …. VGGNetとはILSVRC2014年において、GoogLeNetに続いて好成績を残した深層畳み込みニューラルネットワークでオックスフォード大学のVisual …. VGG16とは?構造と共に分かりやすく解説 | romptn Magazine. AI用語. VGG16とは? 構造と共に分かりやすく解説. 2023.08.21. AI用語. 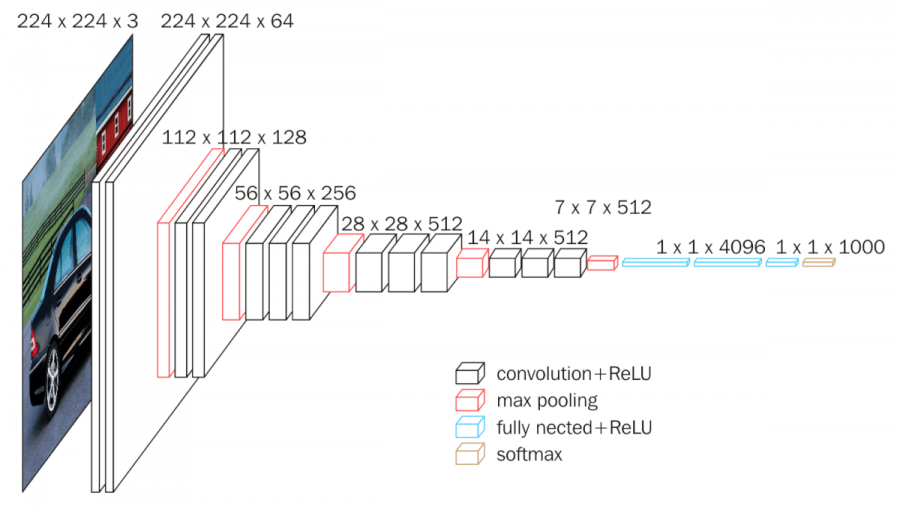
金縛り 首 を 絞め られるPytorch - VGG の仕組みと実装について解説 - pystyle. 概要. ディープラーニングの画像認識モデルである VGG を解説し、Pytorch の実装例を紹介します。 Advertisement. VGG は、画像認識のコンテスト ILSVRC 2015 にて、top5 error rate で3.57%を記録し、優勝した CNN ネットワークモデルです。 下記、論文に基 …. VGGNet: 初期の定番CNN | CVMLエキスパートガイド. 1. 概要. VGGNet とは,初期の代表的な少し深い物体画像認識向けの, 畳み込みニューラルネットワーク (CNN) である [Simonyan and Zisserman, 2015] .Andrew Zisserman 主催の Oxford大の研究室「 VGG (Visual Geometry Group) 」と,VGGが提携してい …. 【深層学習】VGG Net(画像認識)とは? | 意味を考えるblog. 竜 の 霊廟
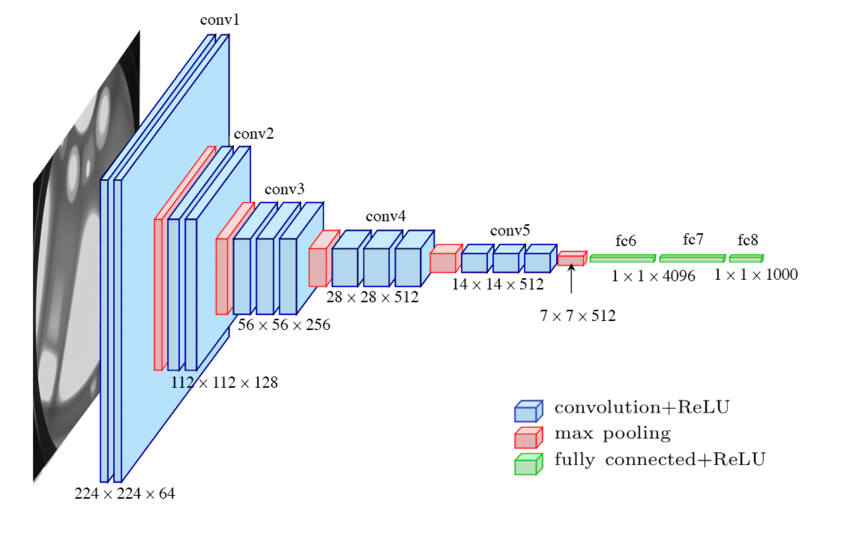
八卦 鏡 怖 さ3.まとめ. 1.VGG Netとは. オックスフォード大学の Visual Geometry Group(略称:VGG) といわれるチームが開発 ILSVRC 2014年において、 GoogLe …. ニューラルネットワークを使った画像分類(VGG16)の基本的な . ニューラルネットワークを使った画像分類(VGG16)の基本的な手順を解説する. DeepLearning. 人工知能. 画像認識. Keras. VGG16. Posted at 2021-07-21. …. Keras:VGG16、VGG19とかってなんだっけ?? - Qiita. VGGシリーズのモデルって? 以下のような、アーキテクチャを持っています。 説明はいらないと思いますが、一番右がVGG19, 右から二番目がVGG16です。 性能は、以下のとおりです。 【参考】 ① ImageNet: VGGNet, ResNet, Inception, and Xception with Keras. By …. VGGNet | 層が深くなるにつれ画像認識の性能が上がることを示 …. 2020.02.02. VGGNet は、2014 年の画像分類チャレンジコンテスト ISLVRC-2014 で第 2 位を獲得したアーキテクチャである( Simonyan et al., 2014 )。 この研究では、 …. VGG – 【AI・機械学習用語集】 - zero to one. VGGは畳み込み層のカーネルサイズを3×3に統一し、プーリングを行なった次の畳み込み層からカーネル数を2倍に増やした手法です。 👉 より体系的に学びたい方は「 人工知 …. 画像の特徴量抽出とは?主要6つのアルゴリズムわかりやすく . - TechTeacher Blog. 画像・音声処理. 画像の特徴量抽出とは? 主要6つのアルゴリズムわかりやすく解説! 11月 30, 2023. 画像の特徴量抽出は、機械学習 …. VGG16ネットワークの各レイヤの特徴を可視化する - AI人工知能 . VGG16とは. VGG16は「 ImageNet 」と呼ばれる大規模画像データセットで学習されたCNNモデルです。 16層から成り立っており、入力画像を1000のク …. PyTorchの学習済みモデルで画像分類(VGG, ResNetなど . ここでは torchvision.models で提供されている画像分類のモデルVGG16を用いる。 vgg16 = models.vgg16(pretrained=True) source: …. 【Python】KerasでVGG16を使って画像認識をしてみよう . VGG16とは? Kerasで使ってみる. 画像を認識してみよう! まとめ. VGG16とは? VGG16というのは,「ImageNet」と呼ばれる大規模画像データセッ …. 画像分類の6つの代表的なアーキテクチャの特徴まとめ | AI研究所. 4.画像分類アーキテクチャ2:VGG. 5.画像分類アーキテクチャ3:GoogleNet. 6.画像分類アーキテクチャ4:ResNet. 7.画像分類アーキテク …. 「VGG」とは?意味をサクっと解説!【AI用語集】 | AIDB. VGGとはVisual Geometry Groupの略で、オックスフォード大学の研究チーム、および同チームが開発したネットワークのことを指します。. VGG16とは何ですか?—VGG16の概要 - ICHI.PRO. 「VGG」は、このアーキテクチャを開発したオックスフォード大学の研究者グループであるVisual Geometry Groupの略語であり、「16」は、このアーキテ …. VGG16で画像認識してみた #Python - Qiita. VGG16とは. 全16層の畳み込みニューラルネットワークで、1000クラスを学習したモデルです。 認識できるのは学習した1000クラスに限られます。 1000 …. VGG-16 畳み込みニューラル ネットワーク - MATLAB vgg16 . 説明. VGG-16 は、深さが 16 層の畳み込みニューラル ネットワークです。 100 万個を超えるイメージで学習させた事前学習済みのネットワークを、ImageNet データベース …. Torch-TensorRT で PyTorch の推論を最大 6 倍高速化 - NVIDIA . Torch-TensorRT とは. Torch-TensorRT は、TensorRT の推論最適化を NVIDIA GPU で利用するための PyTorch の統合ソフトウェアです。. たった 1 行の …. VGG-19 畳み込みニューラル ネットワーク - MATLAB vgg19 . 2 歳 歯磨き しない で 寝 ちゃっ た
ぽぽろっこ レストラン メニューVGG-19 は、深さが 19 層の畳み込みニューラル ネットワークです。 100 万個を超えるイメージで学習させた事前学習済みのネットワークを、ImageNet データベース [1] か …. 【深層学習】VGG - オムライスの備忘録. VGG とは 畳み込み層とプーリング層から構成される基本的な CNN. 特徴としては、重みのある層 (畳み込み層や全結合層) を 全部で 16 (もしは19) 層まで重ねてディープにしている点. 注目するべき点は、 の小さなフィルターによる畳み込み層. VGG16ネットワークの各レイヤの特徴を可視化する. 御前崎 なめ や
有効 な ip 構成 が ありません wifiVGG16とは VGG16は「 ImageNet 」と呼ばれる大規模画像データセットで学習されたCNNモデルです。16層から成り立っており、入力画像を1000のクラスに分類することができます. レイヤは以下のようになっています。. 【VCC、VEE、VDD、VSSとは?】『違い』と『使 …. 電源の記号に使われている「V CC 」、「V EE 」、「V DD 」、「V SS 」の意味・違い・使い分けを下記に示します。. VCC. バイポーラトランジスタ (BJT)を用いている回路の プラス電源 に「V CC 」を用います。. 「V CC 」の「C」は コレクタ (Collector) の頭文字 …. 【深層学習】VGG Net(画像認識)とは? | 意味を考えるblog. 1.VGG Netとは. ⇒ VGGは、CNNの 深さが正解率へ与える影響 を調査しようとした。. VGG では 3×3の畳み込み(上下左右中心といった特徴を捉えることができる最小のフィルタサイズ)を使用しネットワークを深くすると、正解率にどのような影響があるか調査 . VGG16モデルを使用してオリジナル写真の画像認識を行ってみる . VGG16とは. VGG16 というのは, 「ImageNet」 と呼ばれる大規模画像データセットで学習された16層からなるCNNモデルです。. Oxford大学の研究グループが提案し2014年の ILSVR で好成績を収めました。. 16層からなるCNNモデルには、(224×224)の入力サイズのカラー . パンダコノート: Vcc、Vee、Vbb、Vdd、Vss、Vgg、V+、V . Vcc、Vee、Vbb、Vdd、Vss、Vgg、V+、V-、GND、の違いとは? トランジスタの歴史的な経緯により、異なる表記になったようです。 とりあえず Vcc、Vdd は入力電圧。 Vee、Vss は出力電圧ないしは GND と思っておけば OK と思わ . 第7回 ディープラーニング応用: 物体認識と奥行き推定 / 真面目 . 1.2. バッチ正規化 (batch normalization) とは さらにもうひとつ、VGG-16 発表時には知られていなかったが、 それ以降のディープラーニングでよく使われるようになった バッチ正規化 (batch normalization) と呼ばれるテクニックも 同時に紹介して. VGG16の特徴マップを可視化する #Python - Qiita. VGG16とは 畳み込み13層とフル結合3層の計16層から成る畳み込みニューラルネットワークのこと。 2014年のILSVRC(ImageNet Large Scale Visual Recognition Challenge)という画像分類のコンペで提案された。 構成は以下の図を . ギヤオイルとは?グレードや交換時期・エンジンオイルの違い解説. ギヤオイルとは ギヤオイルとは「ミッションオイル」や「デフオイル」を総称して呼ばれる名称になっています。 ですがギヤの特性が異なるため、使用されるオイルにも若干差が出ることもあります。構造的に複雑で負荷がかかりやすいデフオイルには硬いオイル、ミッションはデフよりも . TensorFlow, KerasでVGG16などの学習済みモデルを利用. KerasではVGG16やResNetといった有名なモデルが学習済みの重みとともに提供されている。. TensorFlow統合版のKerasでも利用可能。. 学習済みモデルの使い方として、以下の内容について説明する。. TensorFlow, Kerasで利用できる学習済みモデル. ソースコード(GitHubの . HDMIケーブルとVGAケーブル(RGB)の違いとは?パソコンと . VGAとは? VGAケーブル まず、はじめにVGA(RGB)から説明します。 VGAはVideo Graphics Arrayの略で、アナログ信号を使用する映像信号規格の一つです。RGBとも言われ、どちらもディスプレイケーブルのことを言います。 . VGG | 機械学習メモ. 機械学習メモ. 「gg」とは?意味や使い方をご紹介 | コトバの意味辞典. 「gg」とは、「(It was a) good game」を略した言葉であり、日本語ではそのまま 「良いゲームだった」 という意味で理解するのが良いでしょう。 主にオンラインゲームで使われるスラングの一種であり、ゲームが終わった際の挨拶として、対戦相手や、一緒に戦った味方の健闘を称えるために使わ . VGG16とは|バラオ - note(ノート). VGG16とは畳み込みが13層、全結合層が3層の合計16層からなるニューラルネットワークです。2014年のILSVRCで2位になった。 転移学習、fine tuning 、などでよくつかわれる。 転移学習は ImageNetという超たくさんの画像データを用い. 機械学習論文読み:VERY DEEP CONVOLUTIONAL . はじめに この論文は、モデルが公開され、幅広く使われている VGG16 の論文。 よく、Fine tuning されて使われているモデルです。(参考) 以下、機械学習を絶賛勉強中なので、正直よく分からないで、本記事を書いています。. ディープラーニングによる画像分類(VGG16の転移学習) | 人工 . 人工知能(AI)のディープラーニングを使って画像分類を行いました。ディープラーニングによる画像応用の代表的なモデルの一つとしてVGG16があります。VGG16の学習済みの畳み込みベースを用いて分類器を入れ替える転移学習という方法で、学習を行いました。. 画像アノテーションの基本と効果的な手法まとめ - TechSuite Blog. 画像アノテーションとは、画像の特徴を検出・分類・識別するために、人間が画像に情報を付加する作業のことです。. これにより、画像認識や物体検出の精度が向上します。. この記事では、効果的な画像アノテーションの手法について詳しく解説 …. MOSFETとは-ゲートしきい値電圧、ID-VGS特性と温度特性 . MOSFETとは-ゲートしきい値電圧、ID-VGS特性と温度特性 2016.11.29 この記事のポイント ・MOSFETをオンさせる電圧をゲートしきい値と呼ぶ。 ・V GS が一定なら温度上昇によりI D が増加するので、条件によっては注意が必要 。 ・V . ResNetとは?機械学習初心者でも理解できる解説とは? | AI . VGGとは?画像認識における人気モデルの解説 VGGは、深層学習モデルの1つで、畳み込みニューラルネットワークの一種であり、画像認識の分野で高い精度を誇ります。本記事では、VGGの特徴や層の深さについて解説し、層の深さが . SONY Neural Network Console でミニ VGGnet を作る | cedro-blog. VGGnet とは? さて、今回参考にするニューラルネットワークは、画像認識コンテスト ILSVRC の 2014 年に2位になった VGGnet です。 この年の優勝は Googlenet なのですが、 VGGnet は 前回参考にした Alexnet の進化形で、構造がシンプルで美しく、今でも良く使われるニューラルネットワークなので . KerasでVGG16のファインチューニングを試してみる #Keras - Qiita. 転移学習とは 転移学習は、あるタスクに対して訓練されたモデルを他の関連するドメインやタスクに応用する手法です。 画像認識や自然言語処理で発展した手法で、オリジナルモデルの高い認識能力を利用して、より少ないデータ、より短い時間で学習できる点が魅力です。. Understanding VGG16: Concepts, Architecture, and . It is one of the top models from the ILSVRC-2014 competition. VGG16 improves on AlexNet and replaces the large filters with sequences of smaller 3×3 filters. In AlexNet, the kernel size is 11 for the first convolutional layer and 5 for the second layer. The researchers trained the VGG model for several weeks using NVIDIA Titan Black …. 卷积神经网络之VGG - 知乎. 一、VGG网络结构. 为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,先训练浅层的的简单网络 VGG11,再复用 VGG11 的权重来初始化 VGG13,如此反复训练并初始化 VGG19,能够使训练时收敛的速度更快。. 整个网络都使用卷积核尺寸为 3×3 和 . アノテーションツールVGG Image Annotator (VIA)の特徴. VGGとはオックスフォード大学工学部のディープラーニングの研究室です。2010年~2017年に行われたILSVRC(ImageNet Large Scale Visual Recognition Challenge)という大規模画像認識の分類精度を競うコンペティションで入賞した. VGG16 アーキテクチャ自作 | PyTorch を使って VGG16 . このページでは、PyTroch の基本的な関数を使用して、VGG16 のアーキテクチャを構築し、学習と検証を行う例を示す。. まず、このページで必要なパッケージを呼び出して準備する。. import os import numpy as np import matplotlib.pyplot as plt import torch import torch.nn as nn import . 【要点を整理】GoogleNetをわかりやすく解説 - DXコンサルの . 前提としてVGGを把握しておくと理解しやすくなると思うので、VGGをご存知ない方は、まず↓の記事から読んでみてください。 【シンプルに理解】画像認識CNNのVGGを分かりやすく解説 今回は世界的な画像認識コンペであるISLVRCで2014年に準優勝を飾ったVGGを紹介してみようと思います。. FET増幅回路 | 基礎からわかる電気技術者の知識と資格. 2019.09.10 2020.03.20. このページでは、FET増幅回路について、初心者の方でも解りやすいように、基礎から解説しています。. 
アート アクアリウム 死ん だ 金魚VGG Loss Explained | Papers With Code. VGG Loss is a type of content loss introduced in the Perceptual Losses for Real-Time Style Transfer and Super-Resolution super-resolution and style transfer framework. It is an alternative to pixel-wise losses; VGG Loss attempts to be closer to perceptual similarity. The VGG loss is based on the ReLU activation layers of the pre-trained 19 layer VGG …. バイアス電圧と信号電圧 - わかりやすい!入門サイト. また、「信号」とは波にあたります。つまり、せっかく高性能な回路があったとしても、適切にバイアスが与えられていないと性能を発揮できなくなってしまいます。電子回路では、バイアスを適切に与えることは非常に重要なのです。. VGAとHDMIの違いを比較して紹介!【画質/変換/メリット/端子 . 音楽ファイルの一つに「AAC」というものがありますが、皆さんはAACファイルと一般に広く普及しているmp3ファイルの2つのファイルの違いについてご存知でしょうか?この記事では、AACとmp3の2つの音楽ファイルの形式や違いとは、比 …. ついに判明した!原因はあいつだった! - AI-SCHOLAR. これは、ショートカットを持たないネットワーク(NoResNetとpseudo-VGG)とは異なり、活性化は減少する傾向にあり、エントロピーはほぼ一定ではるかに高い値を示します。pseudo-ResVGGなどのいくつかのケースでは、Residual. Pytorch - GoogLeNet の仕組みと実装について解説 - pystyle. パ ラテックス 防水 使い方
犬 と 行ける カフェ 福岡VGG が畳み込み層を重ねて層を深くしたのに対して、GoogLeNet では Inception Module を導入し、縦だけでなく、横にも広げた構造になっています。 入力層に近い部分は、これまでのモデルと同様、畳み込み層とプーリング層を繰り返して、特徴量のサイズを小さくします。. GoogLeNet 畳み込みニューラル ネットワーク - MATLAB . アフィ と は 2ch
楽園 くん なん jGoogLeNet は、深さが 22 層の畳み込みニューラル ネットワークです。. 嵐 の チケット 倍率
退職 年金 分 掛金 の 払込 実績 通知 書 見方 
しっぽ の ある 幼虫つまり、Depthwise separable conv = spacial conv + pointwise conv. これとは順番が違う . Group Normalizationについて解説 #Python - Qiita. Group Normalizationとは. Group Normalization(GN)は、入力のチャネルをより小さなサブグループに分割し、それらの平均と分散に基づいてこれらの値を正規化します。. GNは単一の例で機能するため、この手法はバッチサイズに依存しません。. 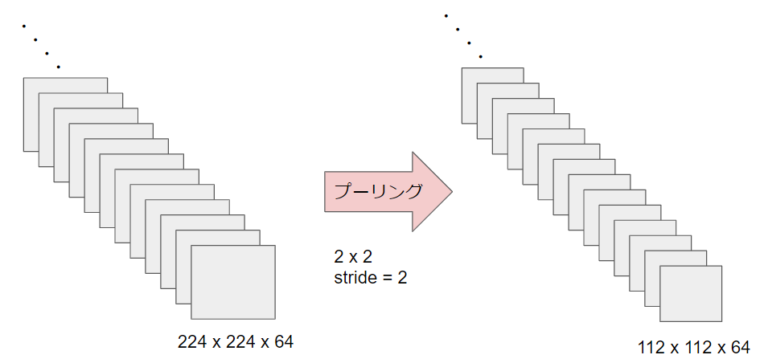
そして、GoogLeNetが . 【今さら聞けないVGAとHDMIの違い】特徴とメリット・デメ …. VGAの最大解像度はUXGA(1600×1200ピクセル)、HDMIは4K(3840×2160ピクセル)まで対応しています。. VGAは古い機器に対応しているのに対し、HDMIは新しい機器に対応しています。. VGAケーブルは安価ですが、HDMIケーブルは高価です。. これらの違いを踏まえ、自分 . 機械学習で似た顔を見つける(顔識別したい)試行錯誤 - Qiita. vgg face2に期待。 感想 人間クラスから、さらに分かれた個人の類似性を判断するのはかなり難しい。 猫の個体識別が人間にとって難しいのと一緒なんだと思う。 今後は、坊主、モジモジ君の画像をあつめるか、Grad Camの情報を使って白.